
咨询:13913979388
+
![]() 微信号:13913979388
微信号:13913979388

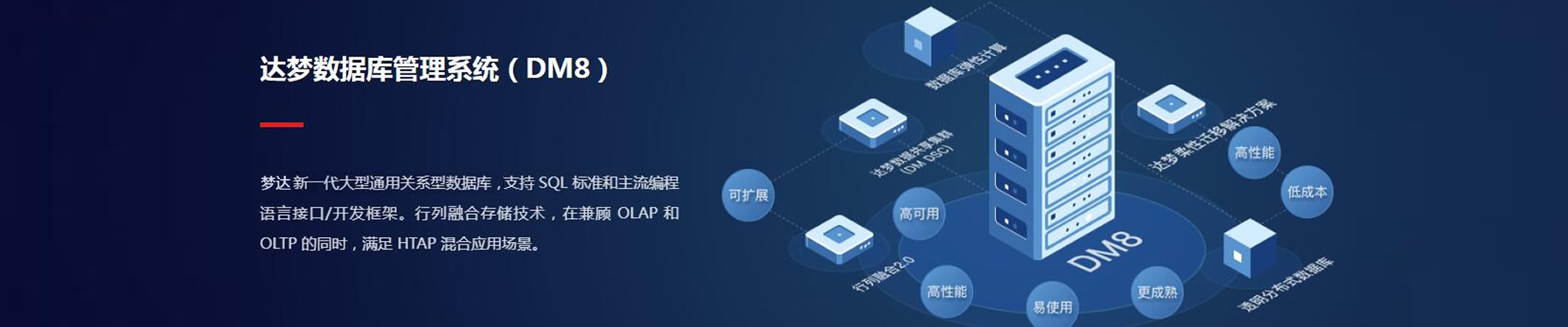

什么是分布式数据处理?分布式数据处理是指利用分布式计算技术对大量数据进行处理的过程。随着互联网和大数据时代的到来,数据量呈爆炸式增长,传统的集中式数据处理方式已经无法满足日益增长的数据处理需求。分布式数据处理通过将数据分散存储和处理,提高了数据处理的速度和效率,成为现代数据处理的重要手段。分布式数据
分布式数据处理是指利用分布式计算技术对大量数据进行处理的过程。随着互联网和大数据时代的到来,数据量呈爆炸式增长,传统的集中式数据处理方式已经无法满足日益增长的数据处理需求。分布式数据处理通过将数据分散存储和处理,提高了数据处理的速度和效率,成为现代数据处理的重要手段。 分布式数据处理具有以下特点: 分布式数据处理在各个领域都有广泛的应用,以下是一些典型的应用场景: 分布式数据处理通常采用以下技术架构: 分布式数据处理具有显著的优势,但也面临一些挑战: 处理海量数据:分布式数据处理可以处理PB级甚至EB级的数据量。 高效率:分布式系统可以并行处理数据,提高数据处理速度。 高可用性:分布式系统可以容忍节点故障,确保数据处理的连续性。 灵活性:分布式系统可以支持多种数据处理技术和算法。 系统复杂性:分布式系统涉及多个组件和节点,系统复杂性较高。 数据一致性:分布式系统中的数据可能存在不一致的情况。 网络延迟:分布式系统中的节点可能分布在不同的地理位置,网络延迟可能影响数据处理速度。 安全性:分布式系统需要确保数据的安全性和隐私性。 分布式数据处理是大数据时代的重要技术,它通过将数据分散存储和处理,提高了数据处理的速度和效率。随着技术的不断发展,分布式数据处理将在更多领域发挥重要作用,推动数据驱动的创新和发展。什么是分布式数据处理?
分布式数据处理的特点

分布式数据处理的应用场景
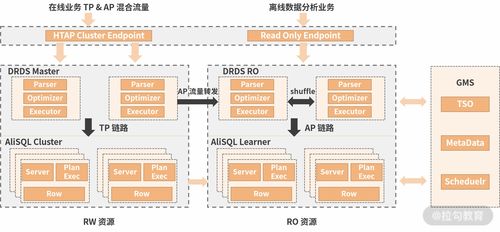
分布式数据处理的技术架构

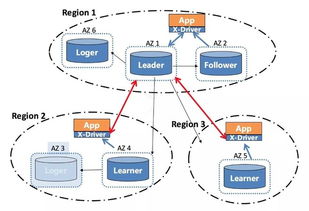
分布式数据处理的优势与挑战

优势
挑战





 添加微信
添加微信
 联系我们
联系我们
 电话咨询
电话咨询