
咨询:13913979388
+
![]() 微信号:13913979388
微信号:13913979388


分布式数据计算:技术原理与应用前景随着互联网和大数据时代的到来,数据量呈爆炸式增长,传统的数据处理方式已经无法满足需求。分布式数据计算作为一种新兴的技术,能够有效地处理海量数据,成为大数据时代的重要技术支撑。本文将介绍分布式数据计算的技术原理、应用场景以及未来发展趋势。标签:分布式数据计算,技术原理
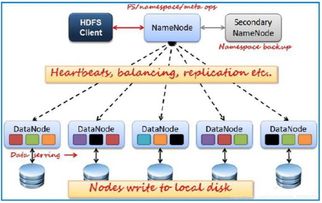
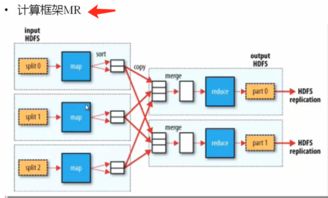
随着互联网和大数据时代的到来,数据量呈爆炸式增长,传统的数据处理方式已经无法满足需求。分布式数据计算作为一种新兴的技术,能够有效地处理海量数据,成为大数据时代的重要技术支撑。本文将介绍分布式数据计算的技术原理、应用场景以及未来发展趋势。 分布式数据计算是指将数据分布存储在多个节点上,通过并行计算的方式处理海量数据的技术。它具有以下特点: 并行处理:分布式计算可以将数据分割成多个部分,在多个节点上同时进行处理,从而提高计算效率。 容错性:分布式计算系统具有高容错性,即使某个节点出现故障,也不会影响整个系统的正常运行。 可扩展性:分布式计算系统可以根据需求动态地增加或减少节点,以适应数据量的变化。 分布式数据计算在各个领域都有广泛的应用,以下列举几个典型应用场景: 搜索引擎:分布式数据计算可以快速处理海量网页数据,提高搜索效率。 推荐系统:通过分布式计算,可以分析用户行为数据,为用户提供个性化的推荐服务。 金融风控:分布式计算可以实时分析金融交易数据,提高风险控制能力。 物联网:分布式计算可以处理海量物联网设备数据,实现智能监控和管理。 分布式数据计算通常采用以下技术架构: 分布式文件系统:如HDFS(Hadoop Disribued File Sysem),用于存储海量数据。 分布式计算框架:如MapReduce、Spark、Flik等,用于并行处理数据。 分布式数据库:如HBase、Cassadra等,用于存储和管理分布式数据。 分布式缓存:如Redis、Memcached等,用于提高数据访问速度。 MapReduce是一种分布式计算模型,由Map和Reduce两个阶段组成。Map阶段将数据分割成多个键值对,Reduce阶段对相同键的值进行聚合。以下是MapReduce的执行过程: Map阶段:将输入数据分割成多个键值对,并输出中间结果。 Shuffle阶段:将Map阶段的中间结果按照键进行排序和分组。 Reduce阶段:对相同键的值进行聚合,输出最终结果。 Spark是一种基于内存的分布式计算框架,具有以下特点: 速度快:Spark采用内存计算,比传统的MapReduce快100倍以上。 易用性:Spark支持多种编程语言,如Scala、Pyho、Java等。 弹性:Spark具有自动容错机制,能够处理节点故障。 Flik是一个流式分布式数据计算系统,具有以下特点: 流批处理:Flik支持流批处理,可以同时处理实时数据和离线数据。 精确的状态管理:Flik具有精确的状态管理机制,能够保证数据的一致性。 容错机制:Flik具有完备的容错机制,能够处理节点故障。 随着技术的不断发展,分布式数据计算将呈现以下发展趋势: 智能化:分布式数据计算将更加智能化,能够自动优化计算资源,提高计算效率。 边缘计算:分布式数据计算将向边缘计算方向发展,实现实时数据处理。 跨平台:分布式数据计算将支持更多平台分布式数据计算:技术原理与应用前景
标签:分布式数据计算,技术原理

一、分布式数据计算概述
标签:分布式计算,应用场景

二、分布式数据计算的应用场景

标签:分布式计算,技术架构

三、分布式数据计算的技术架构

标签:分布式计算,MapReduce

四、MapReduce:分布式数据计算的核心技术

标签:分布式计算,Spark

五、Spark:新一代分布式数据计算框架

标签:分布式计算,Flik

六、Flik:流式分布式数据计算系统

标签:分布式计算,未来发展趋势
七、分布式数据计算的未来发展趋势







 添加微信
添加微信
 联系我们
联系我们
 电话咨询
电话咨询