
咨询:13913979388
+
![]() 微信号:13913979388
微信号:13913979388

分布式数据库与关系型数据库的区别随着信息技术的飞速发展,数据库技术也在不断演进。分布式数据库和关系型数据库作为两种常见的数据库类型,它们在数据存储、处理和查询等方面有着显著的区别。本文将深入探讨这两种数据库的区别,帮助读者更好地理解它们各自的特点和应用场景。一、数据存储方式关系型数据库(RDBMS)采用集
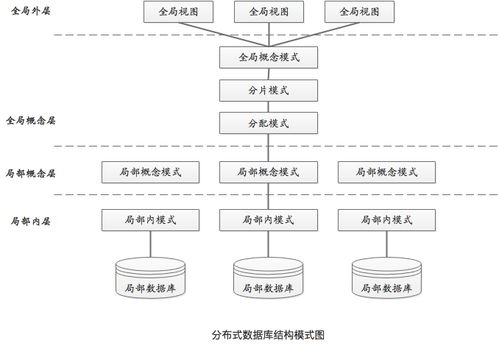
随着信息技术的飞速发展,数据库技术也在不断演进。分布式数据库和关系型数据库作为两种常见的数据库类型,它们在数据存储、处理和查询等方面有着显著的区别。本文将深入探讨这两种数据库的区别,帮助读者更好地理解它们各自的特点和应用场景。 关系型数据库(RDBMS)采用集中式存储方式,所有数据都存储在单个服务器上。这种存储方式便于数据的集中管理和维护,但存在单点故障的风险。而分布式数据库(DDBMS)则将数据分散存储在多个物理节点上,每个节点可以独立处理数据请求。这种分布式存储方式提高了数据的可用性和容错性,即使部分节点出现故障,其他节点仍然可以正常工作。 关系型数据库采用关系模型,使用表格形式的数据结构来存储和管理数据。每个表格由行和列组成,每一列都有特定的数据类型和约束条件。这种数据模型具有高度的数据完整性和一致性,便于数据的查询和分析。分布式数据库则采用分片模型,将数据分散存储在多个节点上。每个节点都有自己的数据副本,当需要访问某个数据时,会从相应的节点获取数据。这种数据模型提高了数据的并发性和性能。 关系型数据库通过事务和锁机制来保证数据的一致性。当多个操作同时访问同一数据时,数据库会通过锁机制来确保数据在某一时刻只被一个操作所修改,从而避免数据不一致的问题。分布式数据库在数据一致性方面相对复杂。由于数据分散存储在多个节点上,如何保证不同节点之间数据的一致性成为了一个挑战。常见的解决方案包括使用分布式事务和最终一致性模型来确保数据的一致性。 关系型数据库在面临大数据量和高并发请求时,往往需要通过硬件升级(如增加内存、CPU等)来提高性能。这种扩展方式称为垂直扩展。而分布式数据库则通过增加节点来提高性能,这种扩展方式称为水平扩展。水平扩展可以更好地应对大数据量和高并发请求,提高系统的可扩展性。 关系型数据库适用于需要高度数据完整性和一致性的场景,如金融、电信等行业。这些行业对数据的准确性和可靠性要求极高,关系型数据库可以满足这些需求。分布式数据库适用于需要高并发、大数据量处理的应用场景,如电商、社交网络等。这些应用场景对系统的可扩展性和可用性要求较高,分布式数据库可以满足这些需求。 关系型数据库通常具有较高的性能和较低的成本。这是因为关系型数据库采用成熟的数据库引擎和优化算法,可以快速处理查询和事务。而分布式数据库在性能方面可能受到网络延迟和数据同步等因素的影响,导致性能相对较低。此外,分布式数据库需要更多的硬件和软件资源,成本相对较高。 分布式数据库和关系型数据库在数据存储、处理和查询等方面存在显著的区别。选择合适的数据库类型需要根据实际应用场景和需求进行综合考虑。关系型数据库适用于需要高度数据完整性和一致性的场景,而分布式数据库适用于需要高并发、大数据量处理的应用场景。了解这两种数据库的区别,有助于我们更好地选择和应用数据库技术。分布式数据库与关系型数据库的区别
一、数据存储方式

二、数据模型

三、数据一致性

四、扩展性

五、应用场景

六、性能和价格

七、






 添加微信
添加微信
 联系我们
联系我们
 电话咨询
电话咨询