
咨询:13913979388
+
![]() 微信号:13913979388
微信号:13913979388


分布式数据库的特点随着互联网和大数据时代的到来,分布式数据库因其独特的优势,逐渐成为数据库技术领域的研究热点。本文将详细介绍分布式数据库的特点,帮助读者更好地理解这一技术。标签:数据分布一、数据分布分布式数据库的核心特征之一是数据分布。数据分布意味着将数据存储在多个物理位置,如不同的数据中心、服务器
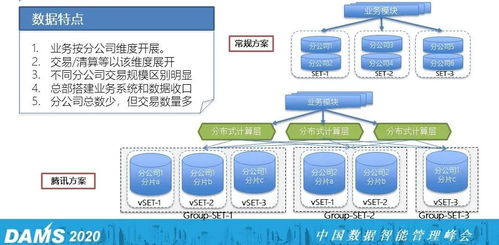
随着互联网和大数据时代的到来,分布式数据库因其独特的优势,逐渐成为数据库技术领域的研究热点。本文将详细介绍分布式数据库的特点,帮助读者更好地理解这一技术。 分布式数据库的核心特征之一是数据分布。数据分布意味着将数据存储在多个物理位置,如不同的数据中心、服务器或地理位置。这种分布方式具有以下优点: 提高可靠性:由于数据分布在多个节点上,即使某些节点发生故障,系统仍然可以继续运行。 减少延迟:通过将数据分布到靠近用户的节点,可以减少数据传输的延迟,从而提升用户体验。 负载均衡:分布式数据库可以将请求均匀分布到各个节点,避免单点瓶颈,提高系统的整体性能。 提高可用性:数据分布在多个节点上,可以通过冗余备份和故障转移机制来保证系统的高可用性。 分布式数据库的透明性体现在以下几个方面: 数据独立性:用户不必关心数据的逻辑分区、物理位置分布和重复副本的一致性问题。 复制透明性:用户不用关心数据库在网络中各个节点的复制情况,被复制的数据的更新都由系统自动完成。 透明性使得用户在使用分布式数据库时,无需关注数据的具体存放位置和复制情况,从而简化了应用程序的开发和维护。 分布式数据库通过以下机制实现高可用性: 数据冗余备份:对数据进行冗余备份,确保数据在节点故障时不会丢失。 故障转移:当某个节点发生故障时,其他节点可以接管其工作,保证系统持续运行。 高可用性是分布式数据库的重要特征,对于保障业务连续性和用户体验具有重要意义。 分布式数据库具有高度的扩展性,主要体现在以下两个方面: 水平扩展:通过增加节点来扩展存储容量和处理能力,满足高并发和海量数据的需求。 垂直扩展:通过升级节点硬件或软件来提高单个节点的性能。 可扩展性使得分布式数据库能够适应业务发展,满足不断增长的数据处理需求。 分布式数据库通过将数据分布到多个节点上,可以并行处理多个请求,从而提高系统的整体性能。并行处理能力主要体现在以下方面: 数据分片:将数据分成多个片段,每个节点负责管理自己的数据分片。 负载均衡:将请求均匀分布到各个节点,避免单点瓶颈。 并行处理能力使得分布式数据库能够高效地处理大规模数据和高并发访问。 分布式数据库通过以下机制实现容错能力: 数据冗余备份:对数据进行冗余备份,确保数据在节点故障时不会丢失。 故障转移:当某个节点发生故障时,其他节点可以接管其工作,保证系统持续运行。 自动检测和纠正错误:系统能够自动检测和纠正错误,保证数据的一致性和完整性。 容错能力是分布式数据库的重要特征,对于保障系统稳定运行具有重要意义。 分布式数据库具有数据分布、透明性、高可用性、可扩展性、并行处理能力和容错能力等特点。这些特点使得分布式数据库成为处理大规模数据和高并发访问的理想选择。随着技术的不断发展,分布式数据库将在未来发挥越来越重要的作用。分布式数据库的特点
标签:数据分布

一、数据分布

标签:透明性
二、透明性

标签:高可用性

三、高可用性

标签:可扩展性

四、可扩展性

标签:并行处理能力

五、并行处理能力

标签:容错能力

六、容错能力

标签:

七、






 添加微信
添加微信
 联系我们
联系我们
 电话咨询
电话咨询